Scope
This vignette documents the shipped release-validation study for
SelectBoost.quantile. The goal is not to claim universal
superiority, but to show how the current prototype behaves against two
direct baselines:
- plain quantile lasso (
lasso) - cross-validated quantile lasso with a 1-SE penalty rule
(
lasso_tuned) -
selectboost_quantile()with tau-aware screening, stronger tuning, complementary-pairs stability selection, capped neighborhoods, and a hybrid support score
The included benchmark artifacts were generated with:
- scenarios from
default_quantile_benchmark_scenarios() tau = c(0.25, 0.5, 0.75)- 4 Monte Carlo replications per scenario
selectboost_quantile(..., B = 8, step_num = 0.5, screen = "auto", tune_lambda = "cv", lambda_rule = "one_se", lambda_inflation = 1.25, complementary_pairs = TRUE, max_group_size = 15, nlambda = 8)- stable support extracted with the hybrid summary score at
threshold = 0.55
summary_path <- system.file(
"extdata",
"validation",
"quantile_benchmark_release_summary.csv",
package = "SelectBoost.quantile"
)
raw_path <- system.file(
"extdata",
"validation",
"quantile_benchmark_release_raw.csv",
package = "SelectBoost.quantile"
)
resolve_validation_path <- function(installed_path, filename) {
if (nzchar(installed_path) && file.exists(installed_path)) {
return(installed_path)
}
candidates <- c(
file.path("inst", "extdata", "validation", filename),
file.path("..", "inst", "extdata", "validation", filename)
)
candidates <- candidates[file.exists(candidates)]
if (!length(candidates)) {
stop("Could not locate shipped validation artifact: ", filename, call. = FALSE)
}
candidates[[1]]
}
summary_path <- resolve_validation_path(summary_path, "quantile_benchmark_release_summary.csv")
raw_path <- resolve_validation_path(raw_path, "quantile_benchmark_release_raw.csv")
validation_summary <- utils::read.csv(summary_path, stringsAsFactors = FALSE)
validation_raw <- utils::read.csv(raw_path, stringsAsFactors = FALSE)
validation_summary$family <- sub("_tau_.*$", "", validation_summary$scenario)
validation_summary$is_high_dim <- grepl("^high_dim", validation_summary$scenario)
validation_summary$mean_f1 <- with(
validation_summary,
ifelse(
(2 * mean_tp + mean_fp + mean_fn) > 0,
2 * mean_tp / (2 * mean_tp + mean_fp + mean_fn),
NA_real_
)
)Overall summary
The first table averages the scenario-level summaries across the full
shipped grid, including the n < p stress regime.
overall <- aggregate(
cbind(mean_tpr, mean_fdr, mean_f1, failure_rate, mean_runtime_sec) ~ method,
data = validation_summary,
FUN = mean
)
knitr::kable(overall, digits = 3)| method | mean_tpr | mean_fdr | mean_f1 | failure_rate | mean_runtime_sec |
|---|---|---|---|---|---|
| lasso | 0.856 | 0.655 | 0.484 | 0 | 0.005 |
| lasso_tuned | 0.900 | 0.735 | 0.383 | 0 | 0.069 |
| selectboost | 0.734 | 0.063 | 0.808 | 0 | 3.794 |
Across the full grid, tuned lasso has the highest average
true-positive rate, but it also carries the highest average
false-discovery rate. The current selectboost_quantile()
release is markedly more conservative: it gives up some recall, but in
exchange it sharply lowers the false-discovery rate across the shipped
benchmark grid and yields the best average F1 score.
Correlated but not high-dimensional regimes
The high_dim scenario is intentionally hard and changes
the picture substantially. Excluding that regime gives a cleaner view of
the correlated and misspecified-noise settings that the current
prototype handles more naturally.
stable_regimes <- subset(validation_summary, !is_high_dim)
stable_overall <- aggregate(
cbind(mean_tpr, mean_fdr, mean_f1, failure_rate, mean_runtime_sec) ~ method,
data = stable_regimes,
FUN = mean
)
knitr::kable(stable_overall, digits = 3)| method | mean_tpr | mean_fdr | mean_f1 | failure_rate | mean_runtime_sec |
|---|---|---|---|---|---|
| lasso | 0.886 | 0.625 | 0.521 | 0 | 0.005 |
| lasso_tuned | 0.936 | 0.719 | 0.406 | 0 | 0.040 |
| selectboost | 0.758 | 0.062 | 0.822 | 0 | 3.894 |
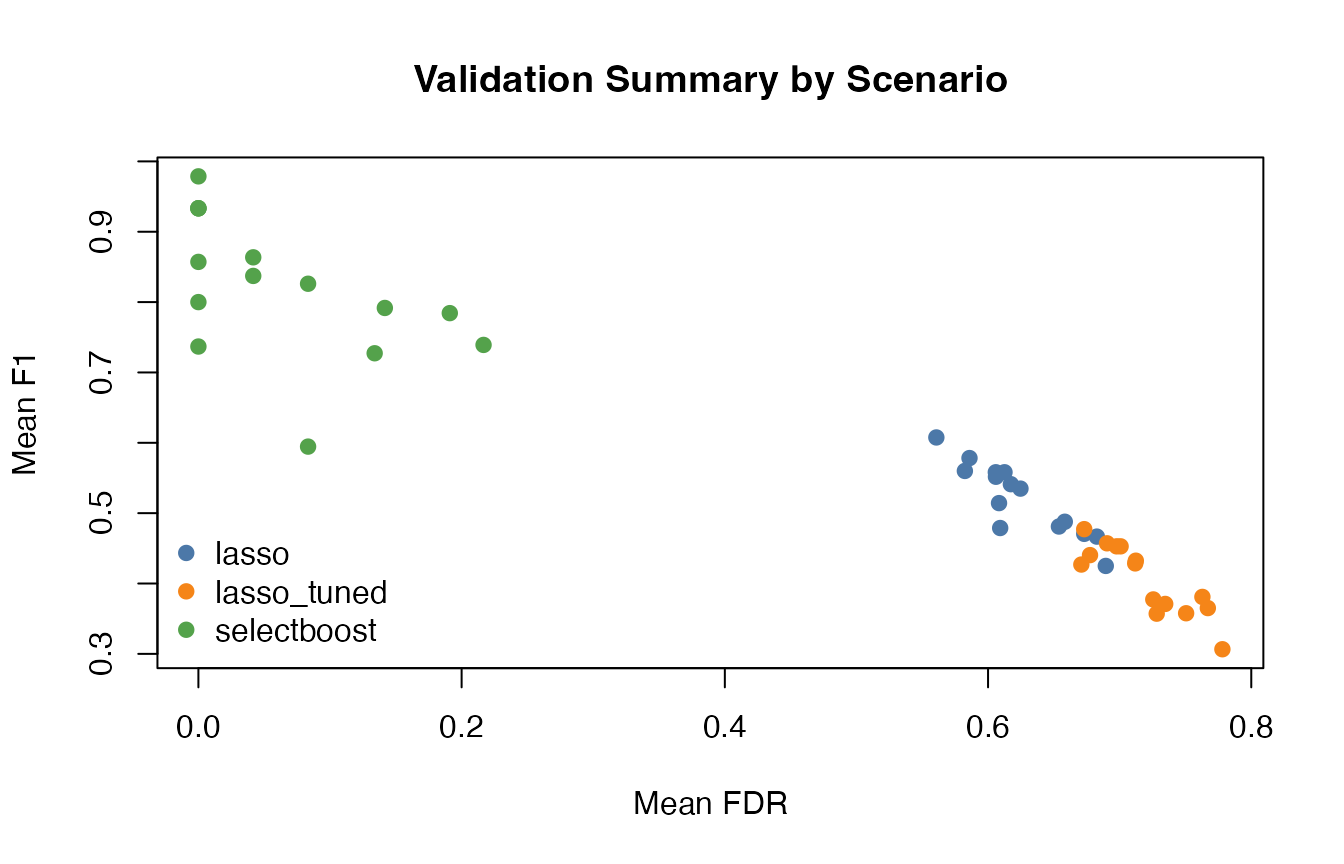
On these non-high-dimensional settings, the shipped study shows a consistent pattern:
-
lasso_tunedhas the highest mean recall -
selectboost_quantile()has the lowest mean false-discovery rate by a large margin -
selectboost_quantile()also has the highest mean F1 score on the shipped grid -
selectboost_quantile()remains slower than either lasso baseline, which is expected because it perturbs, subsamples, and refits repeatedly
The family-level breakdown is below.
family_summary <- aggregate(
cbind(mean_tpr, mean_fdr, mean_f1) ~ family + method,
data = stable_regimes,
FUN = mean
)
knitr::kable(family_summary, digits = 3)| family | method | mean_tpr | mean_fdr | mean_f1 |
|---|---|---|---|---|
| block_corr | lasso | 0.806 | 0.682 | 0.454 |
| heavy_tail | lasso | 0.986 | 0.597 | 0.565 |
| heteroskedastic | lasso | 0.861 | 0.643 | 0.503 |
| high_corr | lasso | 0.778 | 0.600 | 0.518 |
| moderate_corr | lasso | 1.000 | 0.601 | 0.565 |
| block_corr | lasso_tuned | 0.917 | 0.754 | 0.345 |
| heavy_tail | lasso_tuned | 1.000 | 0.692 | 0.449 |
| heteroskedastic | lasso_tuned | 0.903 | 0.696 | 0.437 |
| high_corr | lasso_tuned | 0.861 | 0.722 | 0.383 |
| moderate_corr | lasso_tuned | 1.000 | 0.729 | 0.414 |
| block_corr | selectboost | 0.778 | 0.164 | 0.783 |
| heavy_tail | selectboost | 0.792 | 0.014 | 0.876 |
| heteroskedastic | selectboost | 0.611 | 0.075 | 0.708 |
| high_corr | selectboost | 0.708 | 0.059 | 0.797 |
| moderate_corr | selectboost | 0.903 | 0.000 | 0.948 |
plot_df <- stable_regimes
method_levels <- c("lasso", "lasso_tuned", "selectboost")
cols <- c("lasso" = "#4C78A8", "lasso_tuned" = "#F58518", "selectboost" = "#54A24B")
plot(
plot_df$mean_fdr,
plot_df$mean_f1,
col = cols[plot_df$method],
pch = 19,
xlab = "Mean FDR",
ylab = "Mean F1",
main = "Validation Summary by Scenario"
)
legend(
"bottomleft",
legend = method_levels,
col = cols[method_levels],
pch = 19,
bty = "n"
)
High-dimensional stress regime
The high_dim family remains difficult, but it is no
longer a failure mode in the earlier sense of selecting almost
everything. The improved SelectBoost workflow now returns much sparser
and more stable supports than either lasso baseline.
high_dim <- subset(validation_summary, is_high_dim)
high_dim_overall <- aggregate(
cbind(mean_tpr, mean_fdr, mean_f1, failure_rate, mean_support_size) ~ method,
data = high_dim,
FUN = mean
)
knitr::kable(high_dim_overall, digits = 3)| method | mean_tpr | mean_fdr | mean_f1 | failure_rate | mean_support_size |
|---|---|---|---|---|---|
| lasso | 0.708 | 0.804 | 0.300 | 0 | 22.167 |
| lasso_tuned | 0.722 | 0.817 | 0.270 | 0 | 26.250 |
| selectboost | 0.611 | 0.067 | 0.738 | 0 | 3.917 |
The main remaining tradeoff is recall:
selectboost_quantile() is much cleaner than the lasso
baselines in high_dim, but it is still more conservative
and can miss weaker signals. Even so, on the shipped study it achieves
the best mean F1 score in that regime because it avoids the large
false-positive burden of the lasso baselines. This is the main reason
the package is best described as a polished v2 prototype
rather than a finished methodological endpoint.
failure_rows <- subset(validation_summary, failure_rate > 0)
if (nrow(failure_rows)) {
knitr::kable(failure_rows[, c(
"scenario",
"method",
"failure_rate",
"mean_tpr",
"mean_fdr",
"mean_support_size"
)], digits = 3)
} else {
cat("No method failures were recorded in the shipped study.\n")
}
#> No method failures were recorded in the shipped study.Reproducing the study
From a source checkout, regenerate benchmark artifacts into a temporary directory with:
out_dir <- file.path(tempdir(), "SelectBoost.quantile-validation")
system2(
"Rscript",
c("inst/scripts/run_quantile_benchmark.R", out_dir, "4", "0.55")
)The script loads the local package automatically when run from a
source tree. It writes raw results, aggregated summaries, and a
sessionInfo record to the chosen output directory. If no
output directory is supplied, it defaults to a subdirectory of
tempdir(). In the current source tree, that rerun uses the
screening, stronger lambda, complementary-pairs stability,
neighborhood-cap, and hybrid-support defaults defined in the package
benchmark helper.